
밑바닥부터 시작하는 딥러닝(사이토 고키)라는 책을 읽으면서 딥러닝을 다시 공부해보고 있습니다.
오늘의 배운 것
오버피팅을 억제하는 또 다른 방법으로는, 가중치 감소, 드롭아웃이 있다.
오버피팅은 가중치 매개변수의 값이 커서 발생하는 경우가 많다. weight decay의 방법 중 하나로, 가중치의 값을 손실 함수에 부과하는 방법이 있다. 각 파라미터의 제곱의 합을 부과하는 방식을 L2 노름, 각 파라미터의 절댓값의 합을 부과하는 방식을 L1 노름, 파라미터의 절댓값 중 가장 큰 것을 부과하는 방식을 L∞(Max 노름) 이라고 부른다. 일반적으로 L2 노름을 자주 쓴다.
드롭아웃은 뉴런을 임의로 삭제하면서 학습하는 방법이다. train할 때 순전파를 할 때마다 삭제할 뉴런을 무작위로 선택해, 일부 뉴런만을 이용해 학습을 한다. test할 때는 드롭아웃 하지 않고 모든 뉴런을 활용해서 진행한다.
앙상블 학습은 개별적으로 학습시킨 여러 모델의 출력을 종합(평균 또는 투표의 방식)하여 결과를 추론하는 방식이다. 드롭아웃은 앙상블 학습과 비슷한 효과를 하나의 네트워크로 구현했다고 생각할 수도 있다.
해본 것
아래는 은닉층의 뉴런 개수가 64개인 5층 네트워크에서 배치 정규화만을 사용해 실행해본 모습이다. test_acc는 높긴 했지만, train_acc가 거의 1에 수렴해버렸다.
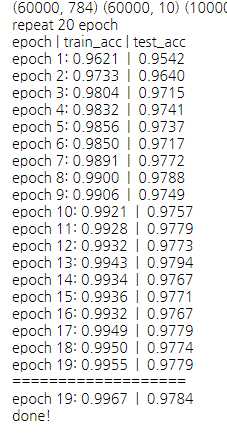
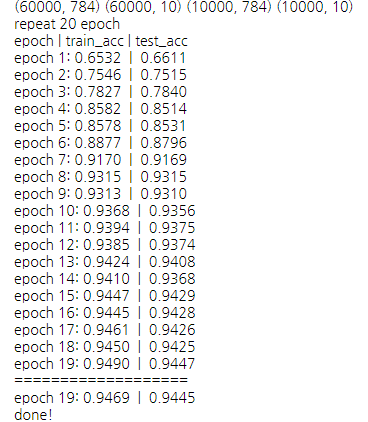
아래는 배치 정규화에서, 각 층에 드롭아웃까지 적용해서 학습시킨 모습이다. 드롭아웃 비율을 0.5로 너무 높게 설정했는지, 상대적으로 정확도는 낮지만, 오버피팅을 줄여주었다는 것을 알 수 있다. (드롭아웃 비율을 0.2로 했을 때는 train_acc가 0.98에 수렴하는 모습을 보였다.)
실습한 코드는 https://github.com/woduq1414/deep-learning-without-tensorflow 에 있습니다.