
밑바닥부터 시작하는 딥러닝(사이토 고키)라는 책을 읽으면서 딥러닝을 다시 공부해보고 있습니다.
오늘의 배운 것
초기 가중치를 균일한 값으로 설정해서는 안 된다. 그 이유는 오차역전파법에서 모든 가중치의 값이 똑같이 갱신되기 때문이다. 따라서 무작위로 설정한다.
가중치를 설정하는 방법으로 Xavier, He 초깃값이 있다. Relu를 Activation 함수로 사용할 때는 He 초깃값을 사용하는 것이 효과적이라고 알려져 있다.
해본 것
weight_init_std = 0.01
initializer =layer.initializer
if isinstance( initializer , Initializer.Std):
weight_init_std = initializer.std
elif isinstance( initializer , Initializer.He):
weight_init_std = np.sqrt(2.0 / input_size)
elif isinstance( initializer , Initializer.Xavier):
weight_init_std = np.sqrt(1.0 / input_size)
self.params[f"W{layer_len}"] =weight_init_std * np.random.randn(input_size, hidden_size)
self.params[f"b{layer_len}"] = np.zeros(hidden_size)
Weight Initialize 를 구현했다. 그 동안 weight를 표준편차가 0.01이고 평균이 0인 정규분포에서 랜덤으로 초기화했었지만 He, Xavier 가중치 초기화법을 쓸 수 있게 되었다.
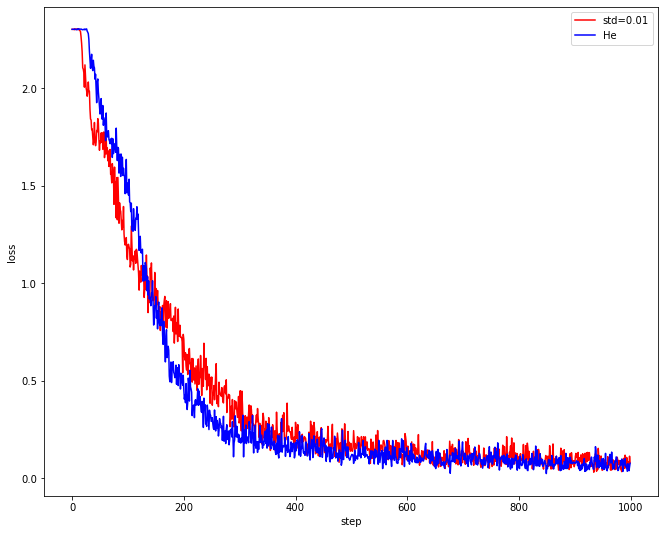
이는 Adam Optimizer를 사용했을 때,
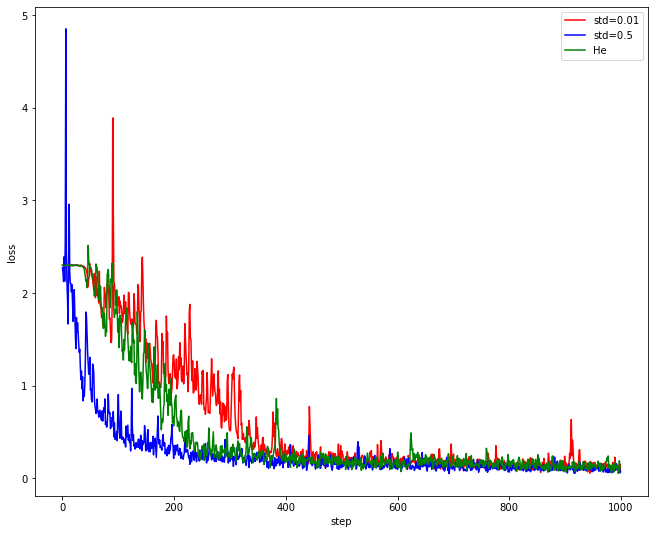
이는 SGD Optimizer를 사용했을 때인데, 내가 구현을 잘못한건지, 딱히 확연히 좋은 지는 잘 모르겠다.. 나중에 한 번 조사해봐야겠다.
실습한 코드는 https://github.com/woduq1414/deep-learning-without-tensorflow 에 있습니다.