
밑바닥부터 시작하는 딥러닝(사이토 고키)라는 책을 읽으면서 딥러닝을 다시 공부해보고 있습니다.
해본 것
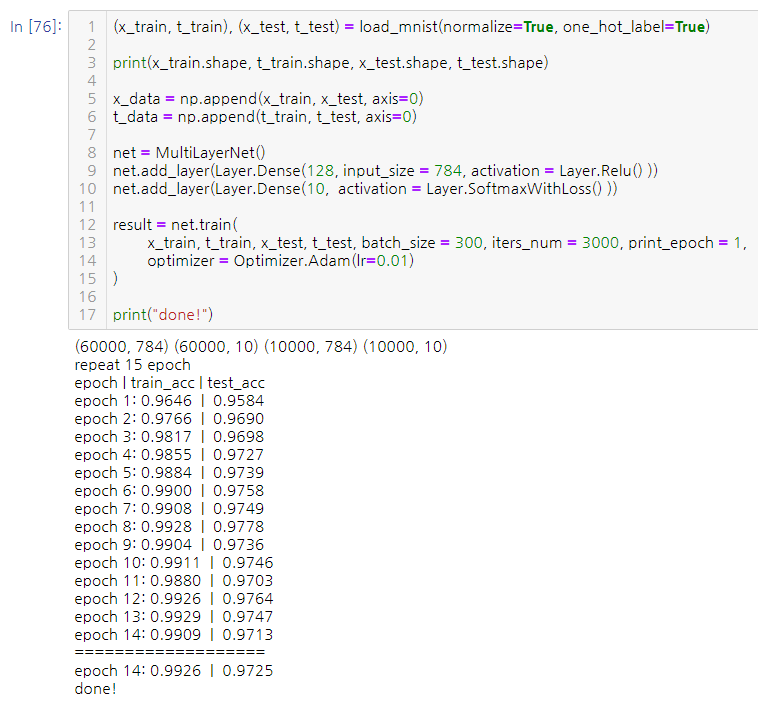
MNIST 숫자 분류를 새로 만든 프레임 워크를 통해 진행해보았다. 은닉층의 뉴런 개수를 128개로 늘렸더니 97%까지 도달할 수 있었다.
Optimizer에 따라 어떤 성능을 보이는 지 알아보기 위해 여러 번 train을 해보고 그래프로 시각화해 보았다. SGD, Momentum, RMSprop, Adam 4개의 Optimize 방식으로, learning rate 를 0.001 에서 1까지 조절해보면서 나타내보았다. (Optimizer마다 momentum, decay_rate 등의 다른 하이퍼 파라미터들이 있긴 하지만 일단 learning rate만 조절했다.)
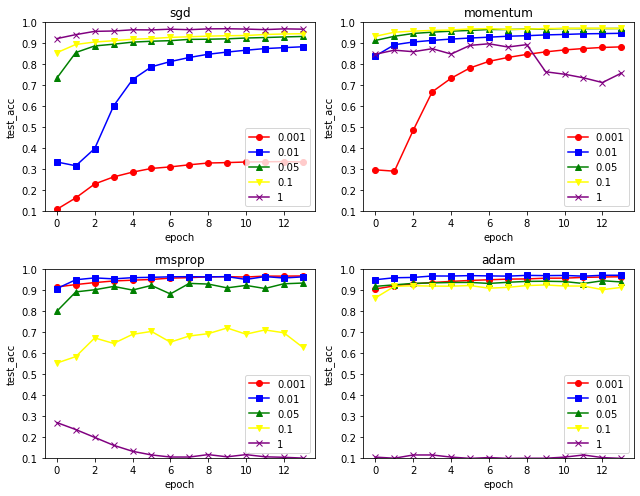
RMSprop 와 Adam은 초반부터 높은 정확도를 보여주었다. 다만 learning rate가 너무 크면 거의 10개 중에 하나를 찍는 수준으로 예측을 하였다.
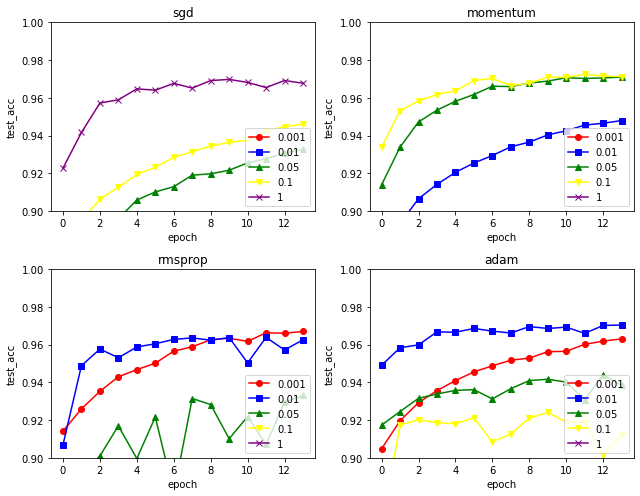
위는 y축 0.9~1.0 구간을 확대한 그래프인데, 0.001부터 learning rate가 높아질 수록 진동하려는 기미가 보이다가 너무 높아지면 제대로 예측을 못하는 상황이 보여진다.
최종적으로 이 경우에서는 SGD(lr : 1) 과 Adam(lr : 0.01)의 정확도가 가장 높았다.
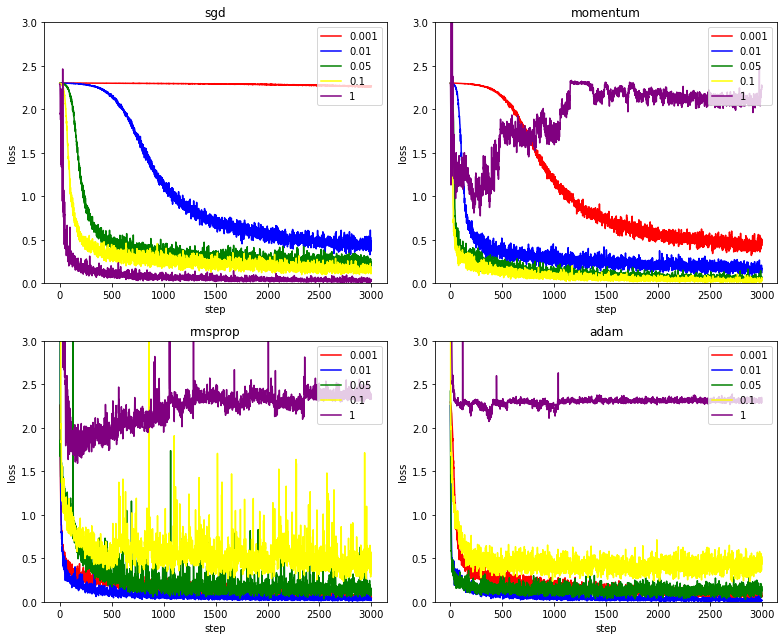
이는 step마다의 loss 그래프 인데, 흥미로운 점은, RMSprop는 높은 learning rate를 주었을 때 loss의 진폭이 컸다. 다만 Adam은 그냥 loss 가 높은 상태에서 상대적으로 작은 진폭으로 일정하게 유지하는 모습을 보였다.
실습한 코드는 https://github.com/woduq1414/deep-learning-without-tensorflow 에 있습니다.