
밑바닥부터 시작하는 딥러닝(사이토 고키)라는 책을 읽으면서 딥러닝을 다시 공부해보고 있습니다.
오늘의 배운 것
지금까지 수치 미분법이나 역전파법을 통해 기울기를 구하고, 기울어진 방향으로 매개변수 값을 갱신하는 것을 반복하여 cost를 줄였다. 이것을 확률적 경사 하강법 (SGD) 라고 부른다. 인터넷을 찾아보니 경사 하강법에는 BGD도 있다고 한다. 이는 전체 데이터에 대해 optimize를 수행하는 것이다. SGD는 mini-batch에 대해 optimize를 수행한다. 일부분 데이터만 가지고 optimize를 진행하므로 BGD 보다 더 빠르고, 메모리도 적게 사용하며, local optimal에 빠질 위험이 적다고 한다.
하지만 SGD도 문제점이 있다. 비등방성(방향에 따라 기울기가 달라지는 함수 라고 한다.) 함수에서는 탐색 경로가 비효율적이라는 것이다. 따라서 이를 보완한 다른 방법들이 개발되었다.
Momentum 방식은 관성을 추가한 방식이다. 원래 계산하는 기울기와 한 시점 전의 접선의 기울기 값을 함께 반영하고, local minimum에 빠질 가능성을 줄여준다.
AdaGrad는 개별 매개변수에 대해 learning rate을 조정하면서 학습을 진행한다. 많이 움직인 매개변수일 수록 더 적은 learning rate를 가지고 학습을 진행한다. 하지만 학습이 계속되면 갱신정도가 너무 약해져서 전혀 갱신하지 않게 될 수도 있다. 이 문제를 개선한 기법으로 RMSProp 이 있다.
Adam방식은 직관적으로 봤을 때 AdaGrad와 Momentum 방식을 융합해서 만든 방식이라고 한다. 또한 하이퍼파라미터의 편향 보정을 진행해 모멘텀 방식을 개선하였다고 한다. 나중에 더 알아봐야할 것 같다.
어느 optimizer를 사용했을 때 효율적인가에 대해서는 하이퍼 파라미터 학습률과 신경망의 구조에 따라 결과는 다를 것이다. 그렇지만 일반적으로 SGD 보다는 위 3개의 학습법이 더 빠르고 정확하다.
해본 것
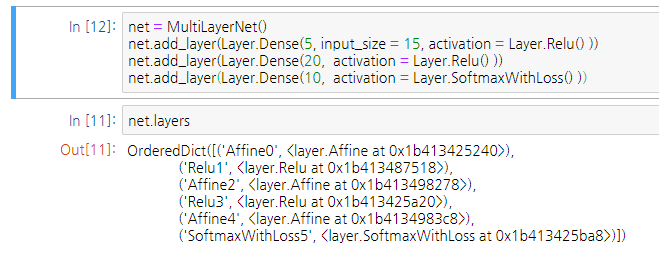
위 코드를 이제 Keras 프레임워크의 방식과 비슷하게 고쳐보려고 시도해보는 중이다.
레이어를 추가하는 부분까지 구현해보았다.
실습한 코드는 https://github.com/woduq1414/deep-learning-without-tensorflow 에 있습니다.