
밑바닥부터 시작하는 딥러닝(사이토 고키)라는 책을 읽으면서 딥러닝을 다시 공부해보고 있습니다.
오늘의 배운 것
데이터를 훈련 데이터와 시험 데이터로 나눠 학습과 실험을 수행한다. 오버피팅 문제를 막기 위함이다.
손실함수에는 오차제곱합과 교차 엔트로피 오차를 사용한다.
데이터셋의 모든 데이터를 대상으로 손실 함수의 합을 구하려면 힘들다. 그래서 훈련 데이터 일부를 추려 학습을 수행하는 것을 미니 배치라고 한다.
경사하강법에서는 기울기 값을 기준으로 나아갈 방향을 정한다. 이를 위해 미분이 필요하다. 수학 시간에 배운 도함수의 정의와 비슷하게 h를 0.0001 정도로 잡고 (f(x+h) - f(x-h)) / 2 * h 를 구하면 미분계수를 구할 수 있다.
경사하강법은 기울기가 0인 장소를 찾지만 그것이 반드시 최솟값이 되지는 않는다. 극솟값이나 안장점, 고원에 위치하게 될 수도 있다.
해본 것
두 개의 레이어가 있는 신경망 네트워크를 만들었고, MNIST 손글씨 인식을 해보았다.
(아직 역전파법 부분은 안 읽었지만, 한 번 사용해보았다.)
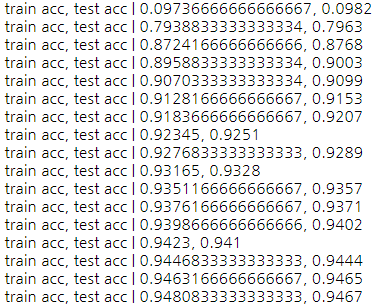
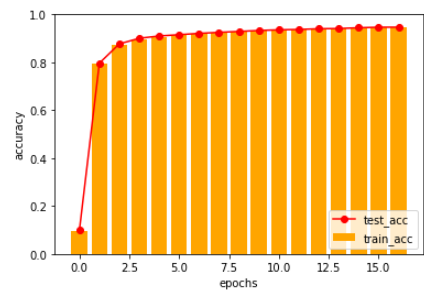
코드를 따라 쳤으니 당연히 잘 된다.
그 다음으로 MNIST가 아니라, 내가 데이터셋을 직접 한 번 만들어서 해보았다.
def make_sample_data_set():
"""
x는 0~999 정수이다.
정답은 x를 100으로 나눴을 때의 몫이다.
"""
x = np.random.randint(999, size=(100,1))
t_data = x.flatten() // 100
# t_data 원핫 인코딩 코드
num = np.unique(t_data, axis=0)
num = num.shape[0]
t = np.eye(num)[t_data]
return x,t
(x_train, t_train), (x_test, t_test) = make_data_set(), make_data_set()
INPUT_SIZE = 1
HIDDEN_SIZE = 30
OUTPUT_SIZE = 10
처음 돌려보았을 때는 정확도가 오락가락 하였다.
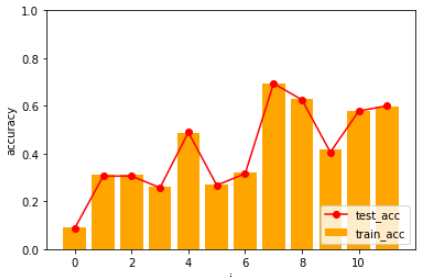
x_train = (x_train - np.mean(x_train)) / np.std(x_train)
x_test = (x_test - np.mean(x_test)) / np.std(x_test)
정규화를 하면 성능이 좋아진다는 말이 떠올라 해봤더니,
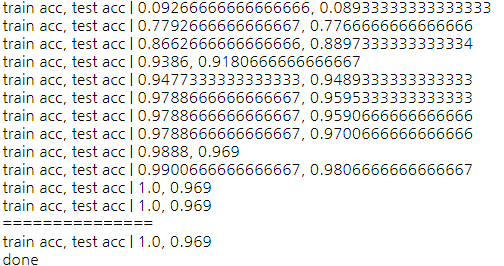
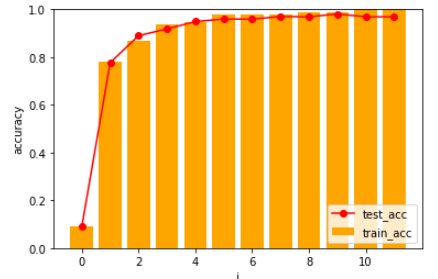
나름 잘 예측하는 것 같다!
실습한 코드는 https://github.com/woduq1414/deep-learning-without-tensorflow 에 있습니다.